预测焦虑与算法破局:如何用QuitoBench重构模型评估体系
时间序列预测领域长期存在一种被忽视的心理状态:算法工程师在面对模型上线时的“虚假自信”与随后的“落地挫败感”。这种焦虑源于模型在经典数据集上的优异表现,与真实业务场景中指标跳水之间的巨大鸿沟。当代码逻辑无误却无法获得预期收益时,问题的根源往往指向了评估体系本身。模型评估如同一次大型考试,而当前时间序列领域的考卷,正面临着严重的信度危机。
针对这一痛点,构建一套科学的评估流程显得尤为重要。首先,必须识别当前基准测试中的系统性缺陷,包括缺乏统一标准、考题偏科严重、测试集数据泄漏以及序列长度不足等问题。这些因素共同导致了排行榜上的名次与实际业务能力之间的脱节。解决这一问题的思路,在于引入更具代表性与工业属性的评估基准,如蚂蚁集团开源的QuitoBench。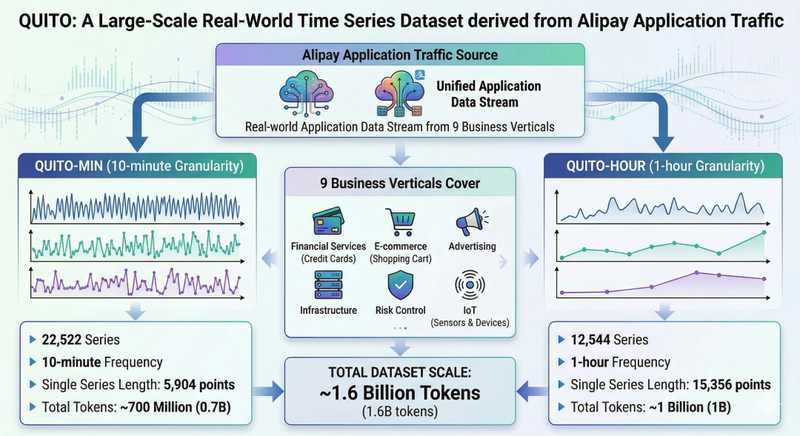
重构评估的实操指南
第一步是建立数据隔离机制。在选择评估工具时,应优先考虑那些具备大规模、真实生产环境背景的数据集。QuitoBench提供的1.6Btokens工业级语料,其核心价值在于与公开预训练语料的零重叠,这从根本上切断了数据泄漏的可能,确保评估结果的纯粹性。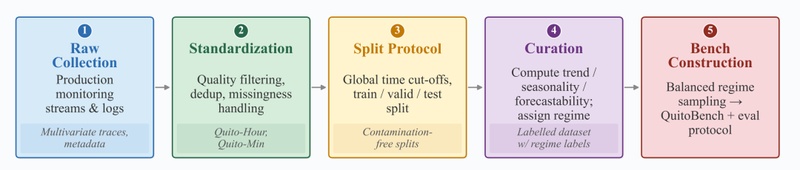
第二步是实施基于统计特征的分类评估。摒弃传统的行业标签分类法,转而采用趋势强度、季节性强度与可预测性三个维度进行交叉分析。这种方法能够将复杂的序列细化为八类TSFRegime,从而实现更精准的诊断,帮助开发者定位模型在特定序列特征下的表现优劣。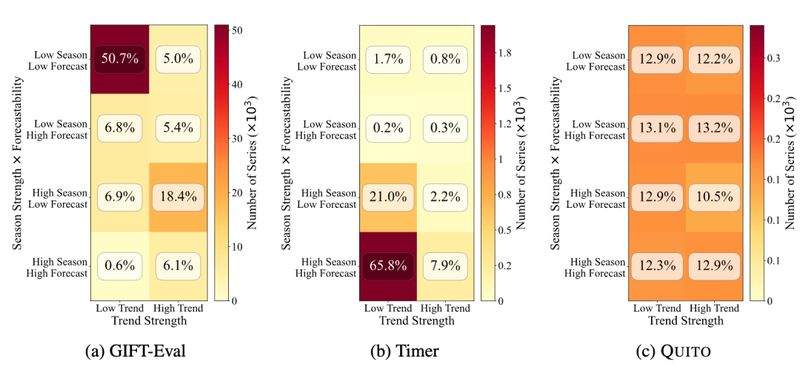
第三步是关注上下文长度与参数规模的权衡。实验数据表明,模型选型应基于业务场景的上下文长度需求。当历史数据窗口较长时,基础模型具备显著优势;而在资源受限的工程场景中,通过优化训练数据而非单纯堆砌参数,往往能获得更高的性价比。开发者应通过增加训练数据量来提升模型性能,而非盲目追求参数规模的增长。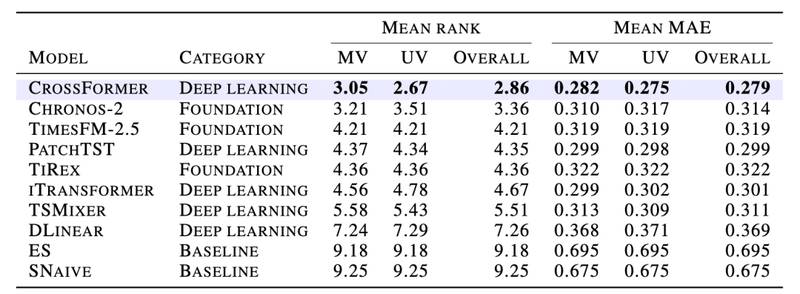
在执行过程中,常见问题往往集中在过拟合与泛化能力不足。通过QuitoBench的均衡采样机制,可以有效避免模型仅在“主流题型”上表现出色。进阶优化方面,建议深入挖掘模型在不同Regime下的表现差异,针对高噪声或低可预测性序列进行针对性调优。这种基于数据内在属性的评估逻辑,不仅能提升预测精度,更能为后续的模型迭代提供清晰的演进路径。



